Performance optimization, or Why does my SQL query take an hour to execute?
October 4th, 2015
I love small performance optimizations that make a huge difference, such as these two from Bruce Dawson of the Chrome team and formerly of Valve Software.
This is the tale of one I found at work in May of this year (2015, for you future people).
I’m posting this because I haven’t seen it documented anywhere online, and hopefully this will save someone else the same headache in future.
In the partiular module I was building, I needed to store and retrieve XML from a database which is hosted by Microsoft SQL Server. I was expecting the XML to be small - just a few kilobytes at most - but it turned out that in certain situations the XML can read 100MB, and even go beyond that.
Whilst trying to troubleshoot network errors on a production system, I noticed that it was taking a very long time to get to the error, even though there was very little code. The pseudocode was something like this:
var xmlArray = LoadXmlFromDatabase();
foreach (var item in xmlArray)
{
SendToServer(item);
}
DeleteItemsFromDatabase(xmlArray);
After adding some logging, I discovered that almost all of the execution time was spent loading the XML from the database. At the advice of a colleague I blindly tried two possible solutions - batching in groups of 10, and then down to one-by-one processing, but to no avail. That was when I went into hardcore performance troubleshooting mode.
There was nothing obvious with a performance analyzer (both Microsoft Visual Studio’s inbuilt one and JetBrains dotTrace), so I set up a standalone repro case and went to down.
The internally built framework at work returned the XML records as a custom implementation of System.IO.TextReader, so I rebuilt that. (Note that this is not the exact code, but a close-enough approximation. I don’t actually remember what the exact code looked like, but this works well enough for a repro.)
The TextReader looked something like this:
class SqlXmlColumnReader : TextReader
{
public SqlXmlColumnReader(SqlConnection connection, string table, string primaryKeyColumn, string xmlDataColumn, object primaryKeyValue)
{
lazyReader = new Lazy<IDataReader>(() =>
{
// If you ever use this in an actual application, ensure that the parameters are
// validated to ensure no SQL injection.
var commandText = string.Format(
CultureInfo.InvariantCulture,
"SELECT [{0}] FROM [{1}] WHERE [{2}] = @pkvalue;",
xmlDataColumn,
table,
primaryKeyColumn);
command = new SqlCommand(commandText);
command.Connection = connection;
command.Parameters.Add(new SqlParameter
{
ParameterName = "pkvalue",
Value = primaryKeyValue
});
// SequentialAccess: "Provides a way for the DataReader to handle rows that
// contain columns with large binary values. Rather than loading the entire row,
// SequentialAccess enables the DataReader to load data as a stream.
// You can then use the GetBytes or GetChars method to specify a byte
// location to start the read operation, and a limited buffer size for the data
// being returned."
var reader = command.ExecuteReader(CommandBehavior.SequentialAccess);
if (!reader.Read())
{
throw new InvalidOperationException("No record exists with the given primary key value.");
}
return reader;
});
}
Lazy<IDataReader> lazyReader;
SqlCommand command;
long position;
public override int Peek()
{
return -1;
}
public override int Read()
{
var buffer = new char[1];
var numCharsRead = lazyReader.Value.GetChars(0, position, buffer, 0, 1);
if (numCharsRead == 0)
{
return -1;
}
position += numCharsRead;
return buffer[0];
}
protected override void Dispose(bool disposing)
{
if (disposing)
{
if (lazyReader != null)
{
if (lazyReader.IsValueCreated)
{
lazyReader.Value.Dispose();
lazyReader = null;
}
}
if (command != null)
{
command.Dispose();
command = null;
}
}
base.Dispose(disposing);
}
}
The repro case created a database, created a table, inserted a large amount of dummy XML data, read it back, then deleted the database. Here’s the code I used for that:
class Program
{
static void Main(string[] args)
{
// Use the same unique ID every time for exact reproducibility
var primaryKey = new Guid("4506E355-B727-4112-82A6-52E0258BAB0D");
var connectionStringBuilder = new SqlConnectionStringBuilder();
connectionStringBuilder.DataSource = @"(localdb)\MSSQLLOCALDB";
// To identify us in SQL Profiler, etc.
connectionStringBuilder.ApplicationName = "Sql Xml Demo";
using (var connection = new SqlConnection(connectionStringBuilder.ToString()))
{
connection.Open();
Console.WriteLine("Connected to LocalDB.");
connection.ExecuteNonQuery("CREATE DATABASE [SqlXmlDemo];");
connection.ExecuteNonQuery("USE [SqlXmlDemo];");
Console.WriteLine("Created SqlXmlDemo database.");
connection.ExecuteNonQuery(@"CREATE TABLE [Foo]
(
[PK] UNIQUEIDENTIFIER NOT NULL PRIMARY KEY,
[XmlData] xml NOT NULL
);");
var stopwatch = new Stopwatch();
stopwatch.Start();
var dummyXml = CreateDummyXml(5 * 1024 * 1024); // Megabytes (technically Mibibytes)
stopwatch.Stop();
Console.WriteLine("Time taken to create 5MB of xml: {0}", stopwatch.Elapsed);
stopwatch.Reset();
// Insert 10MB of XML into our table.
using (var command = new SqlCommand(
"INSERT INTO [Foo] ([PK], [XmlData]) VALUES (@PK, @XmlData);"))
{
command.Connection = connection;
command.Parameters.Add("PK", SqlDbType.UniqueIdentifier).Value = primaryKey;
command.Parameters.Add("XmlData", SqlDbType.Xml).Value = dummyXml;
stopwatch.Start();
command.ExecuteNonQuery();
stopwatch.Stop();
Console.WriteLine("Time taken to insert 5MB of xml: {0}", stopwatch.Elapsed);
stopwatch.Reset();
}
// Actual reading bit
stopwatch.Start();
using (var reader = new SqlXmlColumnReader(
connection,
"Foo",
"PK",
"XmlData",
primaryKey))
{
// Gets immediately garbage-collected, but we've done the work so we have
// our benchmark time.
var text = reader.ReadToEnd();
}
stopwatch.Stop();
Console.WriteLine("Time taken to read 5MB of xml: {0}", stopwatch.Elapsed);
// End actual reading bit
Console.WriteLine("Done!");
connection.ExecuteNonQuery("USE [master];");
connection.ExecuteNonQuery("DROP DATABASE [SqlXmlDemo];");
Console.WriteLine("Dropped SqlXmlDemo database.");
}
}
static string CreateDummyXml(int targetSize)
{
// Base64 uses 4 characters - thus 4 bytes of output - to represent 3 bytes of input.
// Our wrapper tag "<Foo></Foo>" adds 11 bytes;
var builder = new StringBuilder(targetSize);
builder.Append("<Foo>");
var targetBase64Length = targetSize - 11;
if (targetBase64Length > 0)
{
var randomDataSize = targetSize * 3 / 4;
if (randomDataSize > 0)
{
var randomData = new byte[randomDataSize];
using (var rng = new RNGCryptoServiceProvider())
{
rng.GetNonZeroBytes(randomData);
}
builder.Append(Convert.ToBase64String(randomData));
}
}
builder.Append("</Foo>");
return builder.ToString();
}
}
static class SqlExtensions
{
public static void ExecuteNonQuery(this SqlConnection connection, string commandText)
{
using (var command = new SqlCommand(commandText))
{
command.Connection = connection;
command.ExecuteNonQuery();
}
}
}
Thus, the SQL command executed to read in this repro boiled down to:
SELECT [XmlData] FROM [Foo] WHERE [PK] = '4506E355-B727-4112-82A6-52E0258BAB0D';
Looking at the execution plan, it seems extremely straightforward:
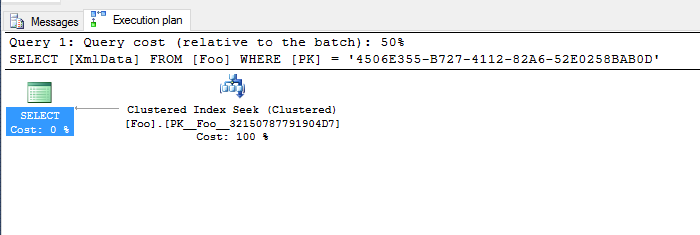
Running it on the other hand, showed a different story. Modified for 1MB, 2MB, 3MB, 4MB and 5MB of XML data, it’s quite clearly taking an exponential performance hit.
C:\temp\SqlXmlDemo\SqlXmlDemo\bin\Debug>SqlXmlDemo.exe
Connected to LocalDB.
Created SqlXmlDemo database.
Time taken to create 1MB of xml: 00:00:00.0086780
Time taken to insert 1MB of xml: 00:00:00.2394446
Time taken to read 1MB of xml: 00:00:01.5584338
Done!
Dropped SqlXmlDemo database.
C:\temp\SqlXmlDemo\SqlXmlDemo\bin\Debug>SqlXmlDemo.exe
Connected to LocalDB.
Created SqlXmlDemo database.
Time taken to create 2MB of xml: 00:00:00.0138875
Time taken to insert 2MB of xml: 00:00:00.3643061
Time taken to read 2MB of xml: 00:00:04.8057987
Done!
Dropped SqlXmlDemo database.
C:\temp\SqlXmlDemo\SqlXmlDemo\bin\Debug>SqlXmlDemo.exe
Connected to LocalDB.
Created SqlXmlDemo database.
Time taken to create 3MB of xml: 00:00:00.0195720
Time taken to insert 3MB of xml: 00:00:00.4948130
Time taken to read 3MB of xml: 00:00:10.4895621
Done!
Dropped SqlXmlDemo database.
C:\temp\SqlXmlDemo\SqlXmlDemo\bin\Debug>SqlXmlDemo.exe
Connected to LocalDB.
Created SqlXmlDemo database.
Time taken to create 4MB of xml: 00:00:00.0252961
Time taken to insert 4MB of xml: 00:00:00.9727775
Time taken to read 4MB of xml: 00:00:21.4877780
Done!
Dropped SqlXmlDemo database.
C:\temp\SqlXmlDemo\SqlXmlDemo\bin\Debug>SqlXmlDemo.exe
Connected to LocalDB.
Created SqlXmlDemo database.
Time taken to create 5MB of xml: 00:00:00.0304792
Time taken to insert 5MB of xml: 00:00:00.7277516
Time taken to read 5MB of xml: 00:00:38.0254933
Done!
Dropped SqlXmlDemo database.
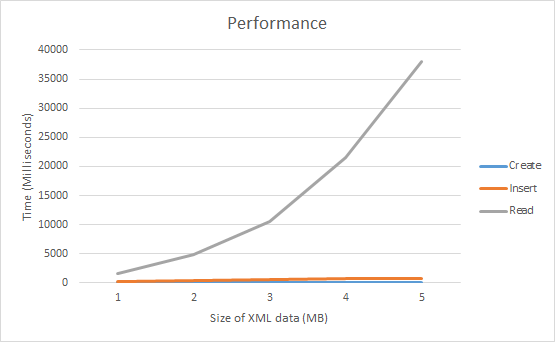
At around the 45MB mark, it took my machine an entire hour to read that data back out of the SQL database, and my machine was no slouch!
Messing around with different options and enlisting the help of the top SQL and .NET experts at my company yielded no answers as to this performance quandry. There was nothing obviously wrong with the code - in a performance analyzer, almost none of the execution time was in my code; most of it was inside IDataReader.GetChars. Running the query itself is also quite fast.
This left me stumped for days, until I “decompiled” the .NET Framework using ILSpy (and later, checked the Microsoft Reference Source). Eventually, I stumbled upon a code branch in System.Data.SqlClient.SqlDataReader, which is only hit if the following three cases are true:
- The column is a Partially Length-Prefixed (PLP) column, which an XML column is.
CommandBehavior.SequentialAccessis specified.- The column is an XML column.
In this case, instead of using the internal GetCharsFromPlpData function, it uses the internal GetStreamingXmlChars function. For some mysterious unknown reason, GetStreamingXmlChars seems to be incredibly slow.
The workaround in this case, then, is to use nvarchar(max) (i.e. multibyte text) instead of xml as the query column type. I changed the query from this:
SELECT [XmlData] FROM [Foo] WHERE [PK] = '4506E355-B727-4112-82A6-52E0258BAB0D';
To this:
SELECT CONVERT(NVARCHAR(MAX), [XmlData]) FROM [Foo] WHERE [PK] = '4506E355-B727-4112-82A6-52E0258BAB0D';
The end result was an increase in performance by an incredible amount.
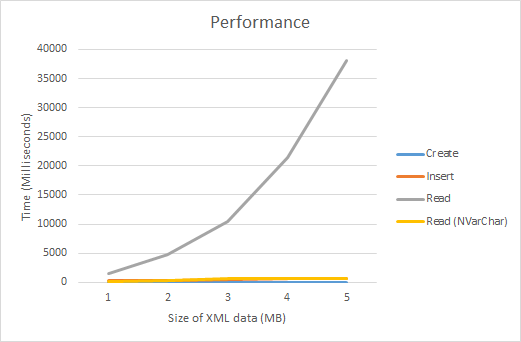
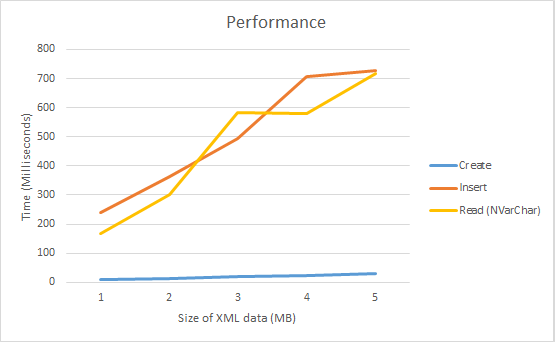
This provided:
- For a 1MB record, a 9.4x performance improvement
- For a 5MB record, a 53.1x performance improvement.
- For a 45MB record, a 3706x performance improvement.
For a proper fix though, I’ve opened this issue on Microsoft Connect. Hopefully this will be fixed in a future .NET Framework release.